Integrations
StornX is deliberately boring about its dependencies. It reuses what your platform team almost certainly already runs, and it works around the things it cannot find.
The dependency matrix
| Integration | Required for | If missing |
|---|---|---|
| Kubernetes | Everything | StornX does not start |
| Prometheus | Everything | Cycle is skipped with a warning until it returns |
| Istio | OptiBalancer | OptiBalancer disables itself, OptiScaler still runs |
| Kube-NetLag | Latency-aware placement | Falls back to "same zone = best" heuristic |
| Metrics-Server / kube-state-metrics | CPU/Memory % visibility | Same - falls back to PromQL alternatives |
You can install StornX into a cluster that has only Kubernetes + Prometheus and still get the autoscaling and zone-spread benefits. Add Istio to unlock adaptive routing; add Kube-NetLag to unlock topology-aware placement.
Istio
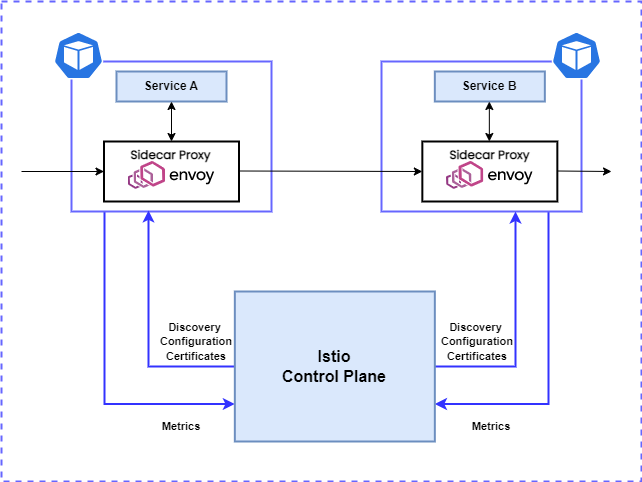
StornX talks to Istio only through the DestinationRule API. Specifically:
- It reads the current
localityLbSettingand per-subset weights. - It patches those fields with new values when its calculations indicate a meaningful drift.
- It never touches
VirtualService,Gateway,EnvoyFilter,PeerAuthentication, or any other Istio CRD.
This narrow surface means StornX is compatible with any reasonably recent Istio release (it has been validated on Istio 1.24.x). It also means rolling Istio back or upgrading it forward does not require touching StornX - as long as the DestinationRule v1 schema is stable, StornX keeps working.
Istio metrics consumed
StornX queries Prometheus for the standard Istio telemetry metrics:
| Metric | Used for |
|---|---|
istio_requests_total | Building the upstream/downstream graph |
istio_request_duration_milliseconds_bucket | P95 response time per route |
istio_request_bytes | Optional bandwidth weighting |
No custom Istio configuration is required to expose these - they are emitted by default by every sidecar.
Prometheus
StornX expects a single Prometheus endpoint reachable from inside the cluster. The Helm chart's config.prometheusUrl value defaults to the in-cluster Prometheus service shipped with the Istio addons (prometheus.istio-system.svc:9090), but any Prometheus that scrapes Istio + cAdvisor will work - including Prometheus Operator setups, Thanos, and managed offerings.
StornX does not scrape anything itself, and it does not expose Prometheus metrics of its own (yet - see Roadmap).
Required scrape targets
To get full value from StornX, your Prometheus should scrape:
- Istio sidecars (for service-graph + P95) - standard with any Istio install.
- cAdvisor (for per-Pod CPU/memory) - standard on every kubelet.
- kube-state-metrics (for HPA/PDB awareness in pre-checks) - recommended.
- Kube-NetLag (for node-to-node latency) - only if you want topology-aware placement.
Kube-NetLag
Kube-NetLag is a sister project that runs as a DaemonSet and continuously measures node-to-node round-trip latency, exporting it to Prometheus.
StornX consumes those metrics to refine its definition of "close": two nodes in the same AZ may have very different real latency depending on the underlying instance placement, network ENIs, or hypervisor topology. Kube-NetLag turns that into actual numbers.
Without Kube-NetLag, StornX assumes:
- Same node → lowest latency
- Same zone → low latency
- Cross zone → high latency
That assumption is good enough for the vast majority of multi-AZ clusters, but Kube-NetLag makes the placement strictly better when topology is non-uniform.
Kubernetes
StornX uses the standard Kubernetes client (@kubernetes/client-node) and works with any conformant Kubernetes ≥ 1.19. It has been validated on:
- AWS EKS (1.27 → 1.33)
- Local
kindandminikubeclusters - Self-managed kubeadm clusters
It uses well-known labels only:
topology.kubernetes.io/zonekubernetes.io/hostnameapp.kubernetes.io/*(read for the service graph; never written)
No custom labels, taints, or annotations are required on your existing workloads.
Cooperation with other autoscalers
| Autoscaler | Coexistence rule |
|---|---|
| HPA | StornX defers - placement is still influenced, replica count is owned by HPA |
| VPA | Compatible - StornX reads current requests, VPA can update them safely |
| KEDA | Treated as an HPA for the purpose of deference |
| Cluster Autoscaler | Fully compatible - StornX does not block scale-from-zero or node consolidation |
Cooperation with the default scheduler
StornX does not replace the default kube-scheduler. When OptiScaler decides "this new replica should run on node X", it patches the Pod template with a node selector and lets the scheduler bind it. If the scheduler refuses (taints, capacity, etc.) the Pod stays pending and the next StornX cycle picks a different target.
This is by design: the default scheduler is excellent at the mechanics of binding; StornX is good at the strategy of choosing where. The two roles compose cleanly.
Next: get hands-on with Prerequisites and Installation.