Why StornX?
Kubernetes is excellent at running containers. It is much less opinionated about where those containers should run as conditions evolve and how traffic should be distributed among them. StornX exists because those gaps quietly cost teams money, latency, and reliability every single day.
The four hidden costs of "default" Kubernetes
1. Communication-blind scheduling
The default kube-scheduler decides where a Pod runs once, at admission, based on requests, taints/tolerations and affinity rules. It has no awareness of which Pods will end up exchanging the most requests with each other. The result, on any non-trivial microservice graph, is a layout that looks fair on paper but is full of long-distance hops in practice.
A
frontendPod ineu-central-1acalling acartPod ineu-central-1cadds 1–3 ms of latency to every request and incurs a per-GB egress charge - both invisible to the scheduler that placed them.
2. Random load balancing inside the mesh
Service meshes (and kube-proxy itself) default to round-robin or random load balancing. A slow replica receives exactly as many requests as a fast one until the slow replica gets so bad that it trips a circuit breaker. By then, the user has already seen the latency spike.
3. Single-signal autoscaling
The HPA scales on one metric at a time (usually CPU). It does not consider:
- Whether the new replica will land in a zone that already has too many of its siblings.
- Whether the existing replicas are actually under-utilised in terms of memory, network or P95 response time.
- Whether the deployment is the upstream or downstream of an overloaded service - i.e. the real bottleneck.
The HPA can scale a frontend to 12 replicas while the downstream payment service remains at 2 and continues to be the actual cause of latency.
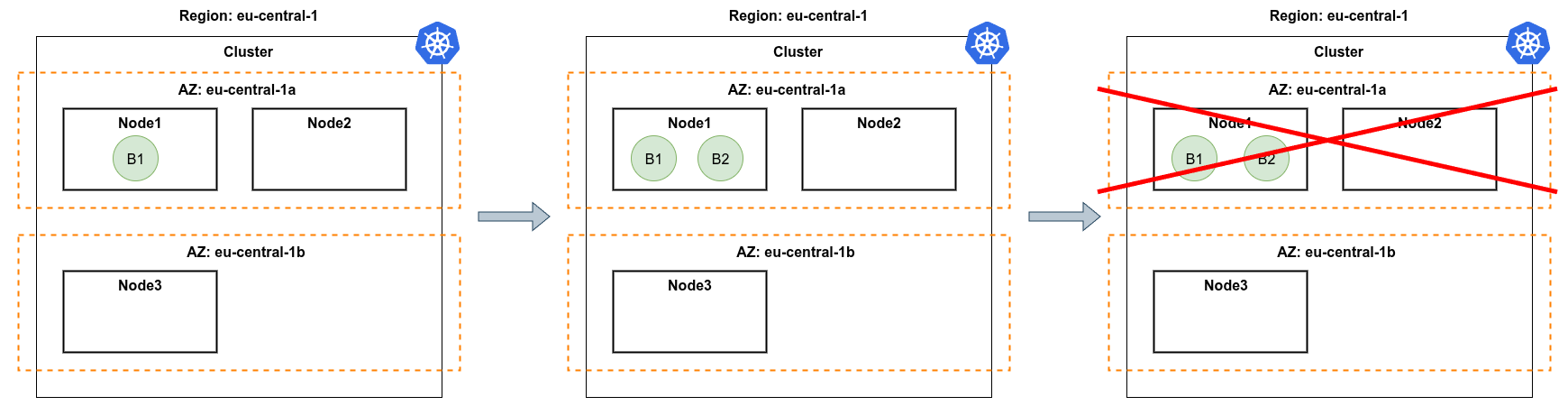
4. Cross-AZ data transfer is a silent bill
In every major cloud provider, inter-AZ traffic is charged per gigabyte in both directions. A chatty microservice graph spread randomly across three zones can spend more on data transfer than on compute. There is no built-in Kubernetes primitive that pushes the cluster toward zone-locality once the workload is running.
What StornX changes
| Concern | Default Kubernetes | With StornX |
|---|---|---|
| Where new replicas land | Resource-fit only | Resource-fit plus proximity to the services they communicate with |
| Traffic split between replicas | Round-robin / random | Adaptive weights based on latency, CPU, and replica count, applied through Istio DestinationRules |
| Reaction to a degraded zone | Manual or after circuit-breakers trigger | Traffic gradually shifts away from the bad zone, new replicas are placed in healthier zones |
| Cost of cross-AZ chatter | Pays the full price | Cuts cross-zone hops by co-locating communicating Pods when fault-tolerance allows |
| Coordination between scaling & routing | None | Scaling decisions trigger rebalancing in the next cycle so new replicas immediately receive proportional traffic |
Concrete benefits
- Lower P95 latency for chatty service graphs - measured end-to-end, not just per-hop.
- Lower cloud bill through reduced inter-AZ data transfer and right-sized replica counts.
- Faster recovery from zone or node degradation - traffic is shifted away gradually instead of catastrophically.
- Operational simplicity - one Helm release replaces a patchwork of custom schedulers, KEDA hacks, and hand-tuned
DestinationRuleweights. - Zero application changes - your services do not need to know StornX exists.
When StornX is the wrong tool
Honesty matters more than marketing:
- Single-AZ clusters - StornX still helps with adaptive routing, but most of the placement value disappears when there is only one zone.
- Workloads without a service mesh - Istio is required for the OptiBalancer component (the OptiScaler still works without it).
- Batch / stateful workloads - StornX currently targets
Deployment-style stateless microservices.StatefulSetsupport is on the roadmap. - Tiny clusters (1–2 services) - the optimization has nothing meaningful to optimize against. Use it where the service graph is rich.
Next: Core Concepts explains the vocabulary StornX uses (upstream/downstream, locality, fault tolerance) before you dive into the architecture.